I'm a deep learning enthusiast with broad interests in ML research and engineering.
I like to understand and explain challenging concepts in the scientific literature, and I enjoy translating abstract theoretical ideas into code. This blog is an excuse for me to do both.
In this post, we will walk through how to build a simple semantic search engine using an OpenAI embedding model and a Pinecone vector database. More specifically, we will see how to build searchthearxiv.com, a semantic search engine enabling students and researchers to search across more than 250,000 ML papers on arXiv using natural language.
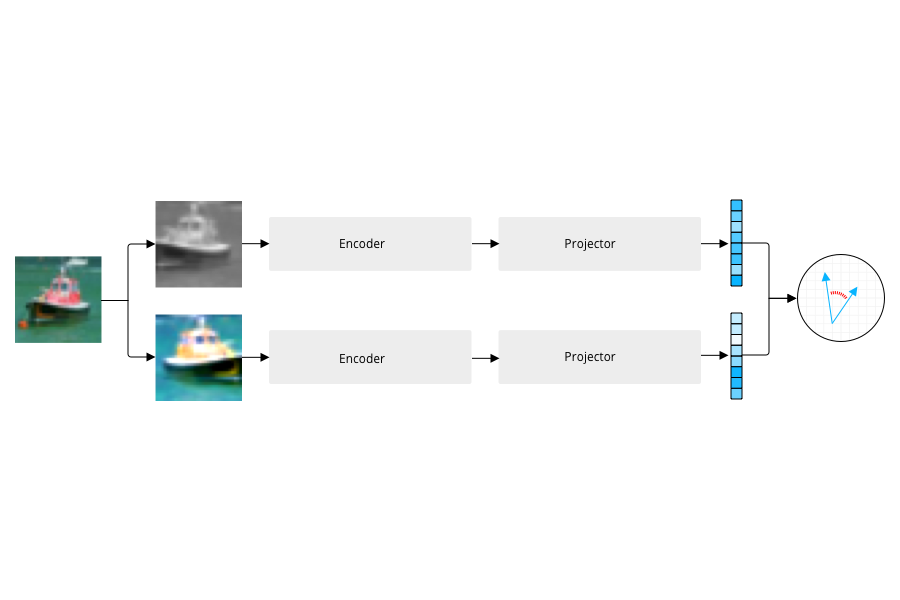
How can we learn good image representations without the need for labeled datasets? Research in this area holds the promise of providing to the vision domain the same abundance of training data that has fueled progress in NLP. In this post, we will explore the problem of SSL through the lens of VICReg, a recent proposal for self-supervised learning of image representations proposed by researchers at Meta and published at ICLR 2022.
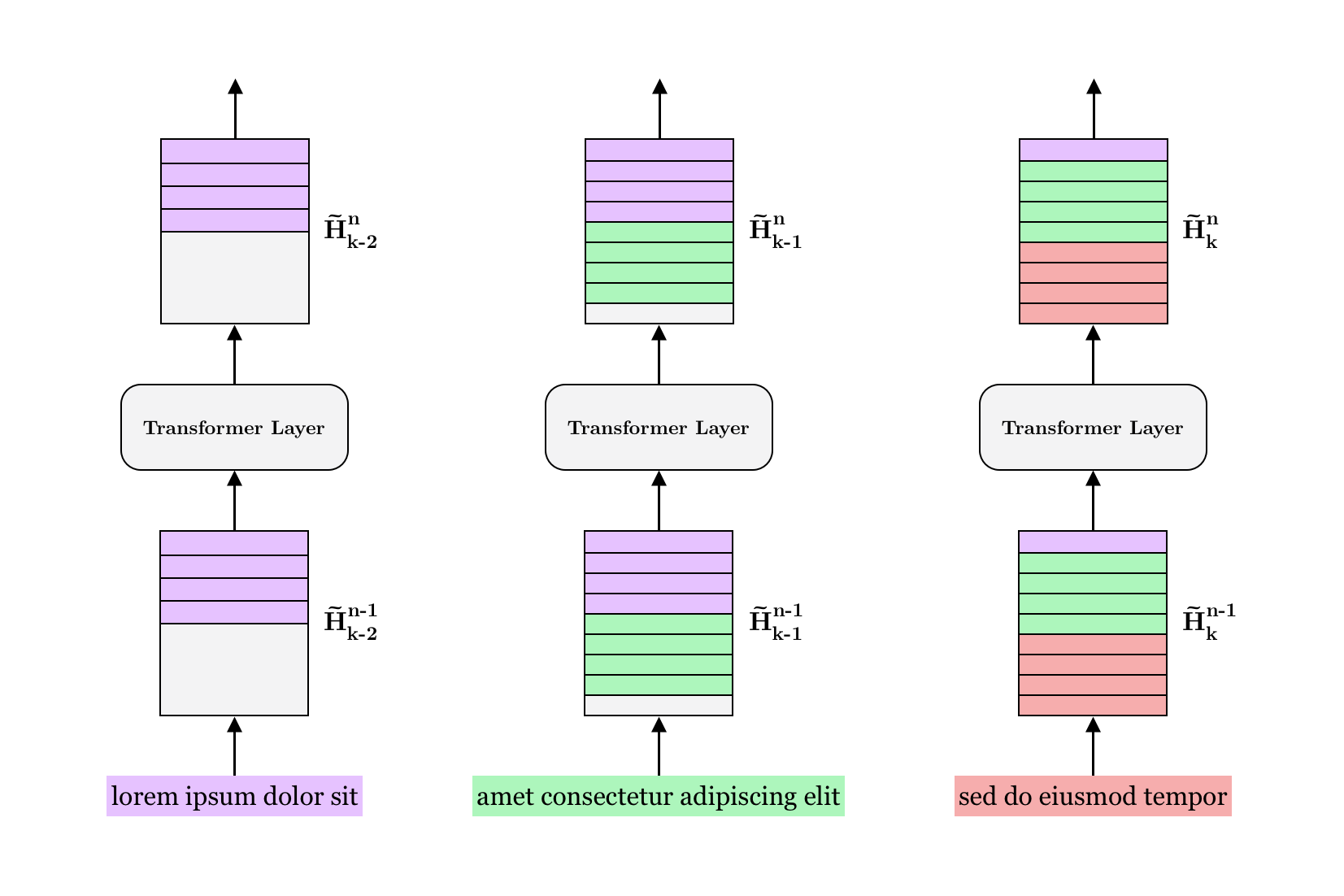
In this post, we will implement a lightweight version of the Transformer-XL model. Proposed by Dai et al. in 2019, Transformer-XL introduced two innovations that, when combined, enable the attention mechanism to have a wider “field of view” and result in significant performance improvements on autoregressive evaluation.
Imagine a chemist in search of a novel drug that will bind to a specific protein in the human body. The chemist is faced with two problems: 1) The space of possible drugs is enormous and 2) the cost of synthesizing a large variety of candidate drugs and evaluating their efficacy is prohibitively expensive and time-consuming.
Trained neural networks are notoriously opaque. They consist of millions — if not billions — of parameters, and when they fail, explaining why is not always easy. This has prompted researchers to invent novel techniques that reveal to us why neural networks behave the way they do. One such technique is DeepDream, which besides being a useful research tool is also really fun!